Recently Nokia made Navigation free atleast in India. However if you now tried to connect for free navigation it still asks for you go to the store. The reason for this is that Nokia has allowed free Navigation using Ovi Maps only on the new version of the software.
So if you have bought your phone couple of weeks ago there is a very good chance you are on the old version. What you need to do is go to the Nokia site and upgrade your version of Ovi maps to the latest version.
There are two ways of getting this done, one is to download the software on your computer and then Sync with your phone which would then automatically upgrade the version of Ovi Maps that is present on your phone.
The second option is to directly download the software to your phone and run it from there. However this would require a data connection from your service provider.
The link for downloading the software is here
If you want to get the map data stored directly on your computer you should go through this post.
http://piglings.blogspot.com/2010/01/nokia-5230-maps.html
Saturday, February 6, 2010
Saturday, January 9, 2010
Nokia 5230 Maps
My dad just got his Nokia 5230, nice phone that comes with Ovi Maps 3 installed however there were no map data available. Since he didn't have GPRS enabled on his phone I decided to do some digging around to make use of the GPS device bundled into the Nokia 5230.
Credit to symbian underground for helping me get this to work.
The first step is to have you your external card ready. Run Nokia Maps on your phone once before you add any maps or voices. This will create the required folder structure on your memory card. Quit the application after that.
On my Nokia the folder structure is cities with a subfolder called diskcache, filled with 16 subfolders called 0 to 9 and a to f, and each of these folders have another 16 subfolders 0 to 9 and a to f.

For India, download the following file from Nokia itself
India Maps
Extract the zip file into your local computer, once done copy drop the 16 folders called 0-9 and a-f into the diskcache folder of the Nokia 5230. You can do this by connecting your device as a external hard drive via the Micro USB port.
Thats it, maps should now work. You should now disconnect the connection to the computer and only then run maps again.
If you want voice as well download the following files
English or Hindi
Extract all the files into the cities folder. That is it.

For other countries check the maps links here
http://diabo.freehostia.com/symbian/indexmaps.htm
The voice links of other languages are here
http://diabo.freehostia.com/symbian/nokiamaps/voices001.html
If you want to enable free Navigation, do read this post
http://piglings.blogspot.com/2010/02/nokia-5230-free-navigation-maps.html
Hope it helps, do leave me a comments. No files are hosted on this site !
Credit to symbian underground for helping me get this to work.
The first step is to have you your external card ready. Run Nokia Maps on your phone once before you add any maps or voices. This will create the required folder structure on your memory card. Quit the application after that.
On my Nokia the folder structure is cities with a subfolder called diskcache, filled with 16 subfolders called 0 to 9 and a to f, and each of these folders have another 16 subfolders 0 to 9 and a to f.

For India, download the following file from Nokia itself
India Maps
Extract the zip file into your local computer, once done copy drop the 16 folders called 0-9 and a-f into the diskcache folder of the Nokia 5230. You can do this by connecting your device as a external hard drive via the Micro USB port.
Thats it, maps should now work. You should now disconnect the connection to the computer and only then run maps again.
If you want voice as well download the following files
English or Hindi
Extract all the files into the cities folder. That is it.

For other countries check the maps links here
http://diabo.freehostia.com/symbian/indexmaps.htm
The voice links of other languages are here
http://diabo.freehostia.com/symbian/nokiamaps/voices001.html
If you want to enable free Navigation, do read this post
http://piglings.blogspot.com/2010/02/nokia-5230-free-navigation-maps.html
Hope it helps, do leave me a comments. No files are hosted on this site !
Friday, October 2, 2009
SQL Server 2008 Memory Leak / windows server 2008 high memory utilization
Having working with Cubes on SQL Server 2000, I had grown used to the fact that SQL will use and release memory depending on its need and I would be able to track the about of memory each program is utlizing through the task manager tab.
However its important to note the following. With windows server 2008 and SQL Server 2008 ( probably SQL Server 2005) the above mentioned assumptions are completely wrong. SQL Server 2008 will utilize as much memory that is available on the box, in my case 64 GB if any job works with high volumes of data but will NEVER EVER release this RAM back to the system once the job completes.
In short, the memory get reserved for SQL Server 2008 till the service / Server gets restarted. In case SQL needs to run some other job that requires data to be loaded, it internally will flush out the older data and load what it needs and yes even then nothing gets released back to the server.
Also to be noted is that in the task manager, none of this memory is ever shown against any of the processes that are running. Even if you use process explorer (sysinternals) this memory does not show up against SQL Server 2008 there as well.
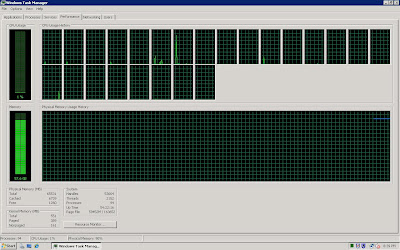
Sadly this leads people ( including me) to come to the conclusion that there is a memory leak in SQL Server 2008. To convince yourself, just limit the amount of memory SQL Server can use and then check out the memory utilization in task manager. It will be that amount plus whatever is required to run your server.
There is article that describes this much more technical detail here ...
http://sqlblog.com/blogs/jonathan_kehayias/archive/2009/08/24/troubleshooting-the-sql-server-memory-leak-or-understanding-sql-server-memory-usage.aspx
Its a good idea to prevent SQL from utilizing the entire memory else the server can become unstable.
P.S. There is no memory leak :)
However its important to note the following. With windows server 2008 and SQL Server 2008 ( probably SQL Server 2005) the above mentioned assumptions are completely wrong. SQL Server 2008 will utilize as much memory that is available on the box, in my case 64 GB if any job works with high volumes of data but will NEVER EVER release this RAM back to the system once the job completes.
In short, the memory get reserved for SQL Server 2008 till the service / Server gets restarted. In case SQL needs to run some other job that requires data to be loaded, it internally will flush out the older data and load what it needs and yes even then nothing gets released back to the server.
Also to be noted is that in the task manager, none of this memory is ever shown against any of the processes that are running. Even if you use process explorer (sysinternals) this memory does not show up against SQL Server 2008 there as well.

Sadly this leads people ( including me) to come to the conclusion that there is a memory leak in SQL Server 2008. To convince yourself, just limit the amount of memory SQL Server can use and then check out the memory utilization in task manager. It will be that amount plus whatever is required to run your server.
There is article that describes this much more technical detail here ...
http://sqlblog.com/blogs/jonathan_kehayias/archive/2009/08/24/troubleshooting-the-sql-server-memory-leak-or-understanding-sql-server-memory-usage.aspx
Its a good idea to prevent SQL from utilizing the entire memory else the server can become unstable.
P.S. There is no memory leak :)
Saturday, August 22, 2009
Excel 2007 OLAP Writeback SSAS 2008
We wanted to build an application based on the Writeback capability of Microsoft. The dream was to have a cube with multiple dimension allowing our users to analyze data by slicing / dicing this cube and based on their analysis make changes to the numbers at various levels.
Once they were happy with the data post changes we were to flow this data to a downstream system. It was to be a highly interactive system for a reasonably competent user to plan target setting by carrying out what if analysis on the existing data.
The front end for the user was Excel 2007 as the navigation / user interface was phenomenon and all our users in our company were fairly competent in Excel.
The path we started down was to have SQL Server Analysis Services 2005 as the backend sitting on a Hexacore 4 processor Windows Server 2008 box. We then enabled the cube for Writeback. The way this works according to me at a high level is that whatever numbers you choose to writeback, it does not make the change directly to your cube, what it does however is to create a writeback partitition that stores the net off data so that you could see the required number on your front end.
Let me explain that a little more with an example, lets say for one depot for one product the value initially was 100. As part of the writeback lets say you want it to be 70. What actually happens is that an entry takes place in the writeback partition for that depot and that product as -30. Based on a join of these two the number dispayed is 70.
While this works perfectly for small sets of data, it fails miserably for larger sets. The solution becomes impractical and very sluggish if the writeback is at an aggregate level and affecting large number of leafs / touples. Post engaging with Microsoft Consulting we confirmed that this was not going to work out for the application we had in mind.
OLAP Writeback sucks, period !!! and even Microsoft didn't have a response :) Now just because the writeback using the writeback partitition is hopeless it does not mean that its the only way to writeback user inputs into the cube.
The path we finally deployed our solution was a combination of the following.
VBA ( Macro coding) / Web services / SQL Server 2008 Integration services and SQL Server 2008 Analysis Services.
The excel that was shared with the users had a custom built macro code that essentially looped through the page / row / column fields to gather the user selections. Care had to taken to be able to loop through both the dimension member as well as the attributes. ( This is feature of SQL Server 2005 + , do read up if you are unaware) Also note it gets more complicated in Pivot 12 as there is extended capability in terms of Value and Label filters, both of which needs to be captured as well incase someone has applied them.
Once all the filters are looped and the details captured, the macro uses this data to frame a create sub cube query that gets passed to the server using a web service. This sub cube that gets created on the fly contains the entire data from the main cube that needs to undergo the writeback / change.
The next step is to strip this newly created sub cube to retrieve the underlying rowset of data that makes up the cube. Once we have that into a table, we have the option of applying pretty much any rule on this data, disaggregation / static values / percentage of existing value / percentage of another value.
Post applying the rule, the data gets updated into the base cube data and an incremental process is carried out and voila you have implemented your writeback.
Just to share some of the numbers, we were able to carry out a writeback affecting 3 Lakh records ( Thats three hundred thousand records :) in India) in a little over 2 minutes with the majority of the time in the incremental processing. This ofcourse will depend on the size and complexity of your own cube.
If your curious about the rest of the design, well since we had the changes in the table we could build an SSIS package to incrementally flow this information down stream into a DB2 environment using OLE/DB2 providers which ofcourse has its own problems in life :)
Once they were happy with the data post changes we were to flow this data to a downstream system. It was to be a highly interactive system for a reasonably competent user to plan target setting by carrying out what if analysis on the existing data.
The front end for the user was Excel 2007 as the navigation / user interface was phenomenon and all our users in our company were fairly competent in Excel.
The path we started down was to have SQL Server Analysis Services 2005 as the backend sitting on a Hexacore 4 processor Windows Server 2008 box. We then enabled the cube for Writeback. The way this works according to me at a high level is that whatever numbers you choose to writeback, it does not make the change directly to your cube, what it does however is to create a writeback partitition that stores the net off data so that you could see the required number on your front end.
Let me explain that a little more with an example, lets say for one depot for one product the value initially was 100. As part of the writeback lets say you want it to be 70. What actually happens is that an entry takes place in the writeback partition for that depot and that product as -30. Based on a join of these two the number dispayed is 70.
While this works perfectly for small sets of data, it fails miserably for larger sets. The solution becomes impractical and very sluggish if the writeback is at an aggregate level and affecting large number of leafs / touples. Post engaging with Microsoft Consulting we confirmed that this was not going to work out for the application we had in mind.
OLAP Writeback sucks, period !!! and even Microsoft didn't have a response :) Now just because the writeback using the writeback partitition is hopeless it does not mean that its the only way to writeback user inputs into the cube.
The path we finally deployed our solution was a combination of the following.
VBA ( Macro coding) / Web services / SQL Server 2008 Integration services and SQL Server 2008 Analysis Services.
The excel that was shared with the users had a custom built macro code that essentially looped through the page / row / column fields to gather the user selections. Care had to taken to be able to loop through both the dimension member as well as the attributes. ( This is feature of SQL Server 2005 + , do read up if you are unaware) Also note it gets more complicated in Pivot 12 as there is extended capability in terms of Value and Label filters, both of which needs to be captured as well incase someone has applied them.
Once all the filters are looped and the details captured, the macro uses this data to frame a create sub cube query that gets passed to the server using a web service. This sub cube that gets created on the fly contains the entire data from the main cube that needs to undergo the writeback / change.
The next step is to strip this newly created sub cube to retrieve the underlying rowset of data that makes up the cube. Once we have that into a table, we have the option of applying pretty much any rule on this data, disaggregation / static values / percentage of existing value / percentage of another value.
Post applying the rule, the data gets updated into the base cube data and an incremental process is carried out and voila you have implemented your writeback.
Just to share some of the numbers, we were able to carry out a writeback affecting 3 Lakh records ( Thats three hundred thousand records :) in India) in a little over 2 minutes with the majority of the time in the incremental processing. This ofcourse will depend on the size and complexity of your own cube.
If your curious about the rest of the design, well since we had the changes in the table we could build an SSIS package to incrementally flow this information down stream into a DB2 environment using OLE/DB2 providers which ofcourse has its own problems in life :)
Sunday, June 21, 2009
Motorola RAZR V3 - Charge via USB on PC
There are other articles that explain this but finding the files for this can sometimes be a problem. Basically the usb does not work directly, software drivers need to be installed on the machine that you want to use to charge.
These drivers can be downloaded here ...
http://ofg.osnn.net/razr/
The detailed article for the same can be found here
http://www.somelifeblog.com/2007/02/motorla-razr-v3-charge-via-usb-on-pc.html
These drivers can be downloaded here ...
http://ofg.osnn.net/razr/
The detailed article for the same can be found here
http://www.somelifeblog.com/2007/02/motorla-razr-v3-charge-via-usb-on-pc.html
Tuesday, May 12, 2009
IBM OLE DB provider for DB2 sql server 2008 / DB2 Administration Client Windows Server 2008
While setting up our production environment we ended up wasting a day as we couldn't create a linked server using IBM OLE DB provider for DB2 as it wasn't showing up in the options. We apparently were trying to install the 32 bit client of the server while we needed the x64 version. After figuring that out we began a hunt to download the required file which in reality was quite painful as it wasn't clearly mentioned anywhere.
In order to save others the trouble, the driver comes along with the installation of the "DB2 Administration Client " as part of the 8.2 versions and as "IBM Data Server Client " in the 9.5 versions. The links in the document are valid for Windows Server 2008 utilizing x64 architecture. If your on 32 bit , you can navigate to the right download from the given pages itself.
The page for the current version of DB2 v9.5 is as follows, make sure you download the "IBM Data Server Client" file. It is part of the fix pack 3b which is latest at the time of this article
http://www-01.ibm.com/support/docview.wss?rs=71&uid=swg21288113
The direct file
ftp://ftp.software.ibm.com/ps/products/db2/fixes2/english-us/db2winX64v95/fixpack/FP3b_WR21447/v9.5fp3b_ntx64_client.exe
In case you are using / want the DB2 v8.2 client, make sure you download the "DB2 Administration Client" file. It is part of the fix pack 17a which is latest at the time of this article
http://www-01.ibm.com/support/docview.wss?rs=71&uid=swg21256105
The direct file
ftp://ftp.software.ibm.com/ps/products/db2/fixes2/english-us/db2winAMD64v8/fixpak/FP17a_WR21442/FP17a_WR21442_ADMCL.exe
Please note that there are different versions for different architectures x32 / x64 / IA64. Download the right file for yourself.
Additionally if you are looking for the Microsoft OLEDB Provider for DB2, it is available as part of the Microsoft SQL Server 2008 Feature Pack, October 2008 located here
http://www.microsoft.com/downloads/details.aspx?FamilyId=228DE03F-3B5A-428A-923F-58A033D316E1&displaylang=en
Do let me know if this has been helpful. Cheers !
In order to save others the trouble, the driver comes along with the installation of the "DB2 Administration Client " as part of the 8.2 versions and as "IBM Data Server Client " in the 9.5 versions. The links in the document are valid for Windows Server 2008 utilizing x64 architecture. If your on 32 bit , you can navigate to the right download from the given pages itself.
The page for the current version of DB2 v9.5 is as follows, make sure you download the "IBM Data Server Client" file. It is part of the fix pack 3b which is latest at the time of this article
http://www-01.ibm.com/support/docview.wss?rs=71&uid=swg21288113
The direct file
ftp://ftp.software.ibm.com/ps/products/db2/fixes2/english-us/db2winX64v95/fixpack/FP3b_WR21447/v9.5fp3b_ntx64_client.exe
In case you are using / want the DB2 v8.2 client, make sure you download the "DB2 Administration Client" file. It is part of the fix pack 17a which is latest at the time of this article
http://www-01.ibm.com/support/docview.wss?rs=71&uid=swg21256105
The direct file
ftp://ftp.software.ibm.com/ps/products/db2/fixes2/english-us/db2winAMD64v8/fixpak/FP17a_WR21442/FP17a_WR21442_ADMCL.exe
Please note that there are different versions for different architectures x32 / x64 / IA64. Download the right file for yourself.
Additionally if you are looking for the Microsoft OLEDB Provider for DB2, it is available as part of the Microsoft SQL Server 2008 Feature Pack, October 2008 located here
http://www.microsoft.com/downloads/details.aspx?FamilyId=228DE03F-3B5A-428A-923F-58A033D316E1&displaylang=en
Do let me know if this has been helpful. Cheers !
Thursday, April 9, 2009
Google Chrome not working / Google Chrome stopped working
I had this really weird issue where google chrome stopped working on my laptop, did some search and I finally found this obscure post on google's own site asking the user to try something to make it work. Interestingly it did, the version for which the solution was written for was different but essentially the method is what is important.
The issue was that on clicking the chrome icon nothing happens, the browser does not load up, and the task manager does not show the process to be running. Not sure what triggered this though.
The solution is to go to the following path in your command prompt
C:\Documents and Settings\(user name)\Local Settings\Application Data\Google\Chrome\Application\(version number)\Installer
Run the following statement
setup.exe --rename-chrome-exe
quit the command prompt with an exit. Chrome started working for me after that, hope it works for you as well. The link of the google page from where I got this from is below
http://www.google.com/support/forum/p/Chrome/thread?tid=2680b41d121dc73a&hl=en
Do let me know if this has helped you, if your feeling generous you could donate a dollar via paypal :)
The issue was that on clicking the chrome icon nothing happens, the browser does not load up, and the task manager does not show the process to be running. Not sure what triggered this though.
The solution is to go to the following path in your command prompt
C:\Documents and Settings\(user name)
Run the following statement
setup.exe --rename-chrome-exe
quit the command prompt with an exit. Chrome started working for me after that, hope it works for you as well. The link of the google page from where I got this from is below
http://www.google.com/support/forum/p/Chrome/thread?tid=2680b41d121dc73a&hl=en
Do let me know if this has helped you, if your feeling generous you could donate a dollar via paypal :)
Subscribe to:
Posts (Atom)
